|
|
For the past several weeks, I have been busily going through tons of data from previous years in an effort to isolate only the data I need for my project. As a reminder, I’m looking at how prairie fire changes the mating scene and mate availability for Echinacea. I am using data from 1996, 1998, 2007, 2009, 2012, 2014, and 2015. With the exception of 2015 when no burn occurred, part of Staffanson Prairie Preserve underwent a controlled burn during each of these years.
From a file containing all seed set data for all plants that the Echinacea Project has ever collected, I extracted data for plants that flowered in both 2015 and at least one of the previous burn years. I ended up with 26 plants that met this description, and I will compare reproductive success of each of these plants on an individual basis in burn years compared to non-burn years.
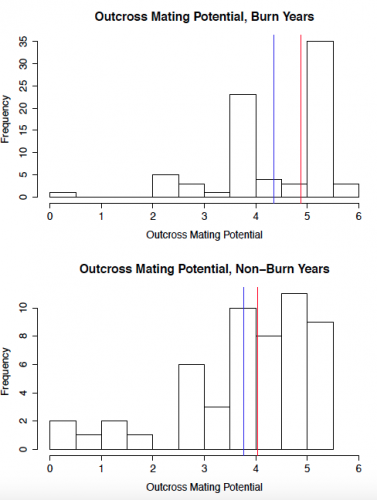
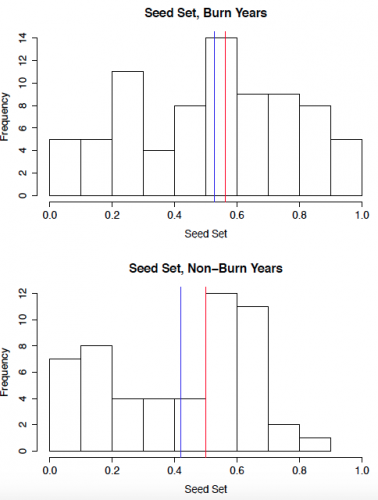
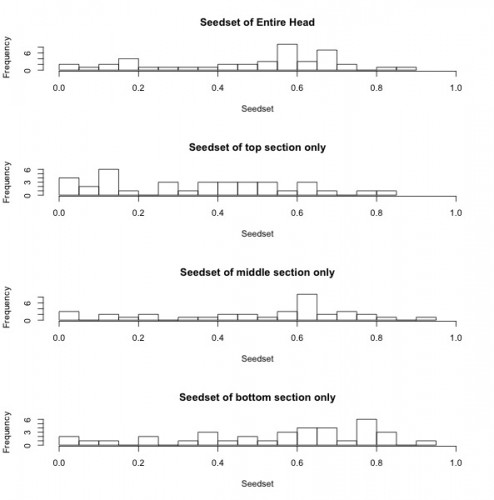
To start out, I created some histograms of the data to get a quick insight into patterns that might be present. In order to roughly quantify the quality of the mating scene for a given plant, I calculated outcross mating potential (OMP), which takes into account the distances to the 6 nearest flowering neighbors. A higher value indicates a greater density of available mates. The second set of histograms shows seed set, with a higher number indicating greater reproductive success. While I will need to conduct statistical analyses to get a better understanding of what these data mean, initial impressions indicate that both the mating scene and reproductive success may be better in burn years.
 
I successfully created a generalized linear model to describe reproductive success at Staffanson Prairie Preserve for the 2015 season. I started out with a model containing distance to the 3rd nearest neighbor, flowering start date, flowering duration, section of head from with the achene came, and all interactions between these main effects. In addition, I included both linear and quadratic terms for distance, start date, and duration. The purpose of including a quadratic term is to test for evidence of curvature in the relationship to seed set.
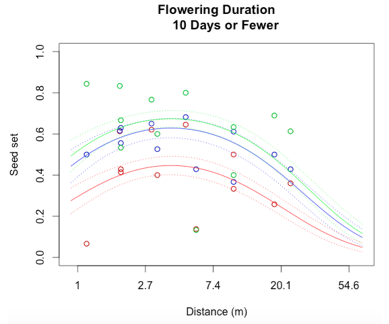
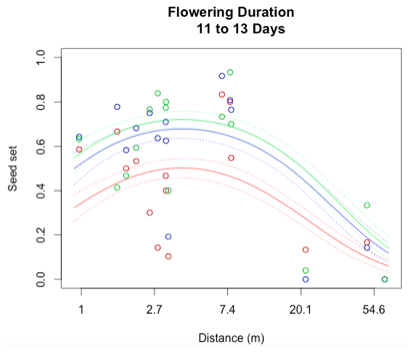
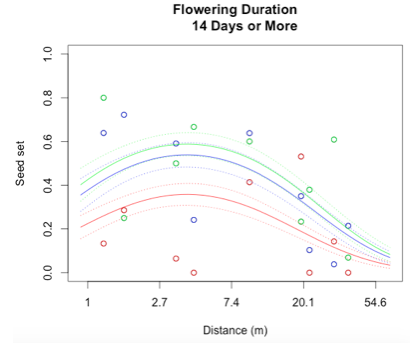
Through a process called backwards elimination, I removed all terms from the model that did not have a significant impact on reproductive success. The final model I came up with contained both linear and quadratic terms distance and start date, as well as the section of head. No interactions were found to be significant. In the plots below, the raw data are shown as points, and the predicted valued from the model are shown as curves. There are three plots of seed set as a function of distance, with the three plots representing low (10 days or fewer), mid (11-13 days), or high (14 days or more) flowering duration. The colors correspond to section of head, with red being top, blue is middle, and green is bottom.
  
While this is an observational study, so attributing causation would be inappropriate, it is helpful to think about why these relationships may exist. The general trend with increasing distance and spatial isolation is that seed set and reproductive success decrease. This is probably because isolated plants have fewer available mates or may be visited by fewer pollinators. However, the relationship is curved and plants in very densely populated areas also have diminished seed set. This may be caused by overcrowding and competition between plants for pollinators in areas of high population density.
Seed set has a similar peak at mid-duration of flowering. One explanation for this phenomenon is that plants that flower for a very short period of time co-flower with fewer potential mates, so a longer flowering time would maximize the number of compatible mates flowering at the same time. However, it is also known that extended flowering can be a sign that the head has not been receiving sufficient pollen, explaining the negative relationship between duration and seed set seen at higher durations.
In the future, this model will be compared to similar models from previous years during which Staffanson underwent controlled burns. Any differences seen between the models may be indicative of how the mating scene changes during the year after a burn.
With all of my data collected and visualized for the heads from Staffanson Prairie Preserve from 2015, it is now time to start with some initial data analysis. As I mentioned in my last post, I will be using R for all of my analyses, taking advantage of skills I learned in Stuart’s class at Northwestern this quarter. I will be creating statistical models based on the data to look for relationships between variables that may influence mate availability and reproductive success. The variables I am specifically looking at are:
- Distance to the kth nearest flowering neighbor. This is a measure of spatial isolation, with greater distance indicating greater isolation. Stuart has found a significant relationship between distance and reproductive success in Echinacea previously (that study can be found here: https://echinaceaproject.org/pub/wagenius2006.pdf)
- Start date and flowering duration. Flowering phenology, the timing and duration of flowering, is perhaps more important than spatial isolation in determining availability of compatible mates. If two plants are very close in space, but they do not flower at the same time, there is no possibility for mating. Previous data has shown that plants flowering earlier in the season have higher reproductive success (https://echinaceaproject.org/pub/isonAndWagenius2014.pdf)
- Section of head from which the achene originated. Because florets at the base Echinacea heads begin flowering first, and the ones at the top flower last, it is possible to examine how reproductive success, and thus the mating scene, differ for a single head across time. The bottom 30 achenes, the middle achenes, and the top 30 achenes are separated to represent the beginning, middle, and end of the timing of flowering.
- Seed set, or proportion of achenes that contain a seed, will be used to quantify reproductive success. This will be the that the model I create will try to predict using the variables I listed above.
In order to create a model, I will be using a technique known as backwards elimination as described in Statistics: An Introduction Using R (Crawley 2015). I will start by creating a statistical model containing my response variable (seed set), and all of my explanatory or predictive variables (isolation, phenology, section of head), along with all interactive effects between the explanatory variables. I will then eliminate a single predictor or interaction at a time and perform an analysis of deviance to determine whether or not that predictor was important to the predictive value of the model. If it is important, I will leave it in, but if it’s not, I will take it out. This process continues until all predictors and interactions left in the model have a significant effect on the response. This model, known as the minimal adequate model, is the simplest model that still includes all important variables.
Now that I’ve finished collecting data from the Echinacea heads collected from Staffanson Prairie Preserve in 2015, I am able to start doing some data analysis. While the ultimate goal is to compare the data from 2015, a non-burn year, to previous burn years, I first want to come to a good understanding of what reproductive success looked like in 2015.
For all of the analyses I will be doing, I am using computer software called R. R is a very flexible program that allows you to employ a wide range of graphical and statistical techniques including modeling, running tests, and clustering. Although R does have a somewhat steep learning curve, I have been learning many useful techniques in Stuart’s class on R at Northwestern and am confident in my ability to properly analyze the data I have collected.
The histograms below show seedset, which is the proportion of achenes that contain a seed and can range from zero to one, for the entire head, as well as for the top, middle, and bottom sections of each head. For the entire head, the sample has a range from 0 to 0.86, with a mean of 0.48 and a median of 0.57. While the middle and bottom portions of the head had similar seedsets, the top portions of each head appear to have lower seed set on average when compared to the rest of the head. This is consistent with the findings of previous years and suggests that florets that are receptive to pollen later in the season may have diminished reproductive success.

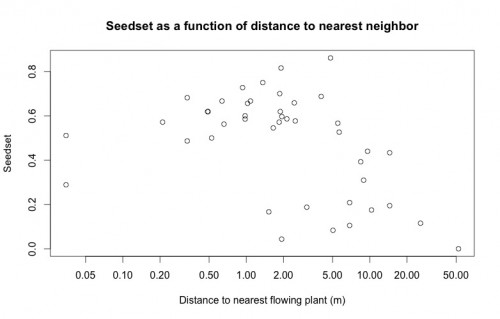
An important variable in Echinacea reproduction, spatial isolation, is modeled in the below plot as a predictor of seedset. This plot highlights the importance of doing a careful visual exploratory data analysis before diving into more complicated statistical analyses. While there does appear to be the expected inverse relationship between seedset and spatial isolation, upon looking at this plot Stuart was immediately able to tell me that the two points on the left of the plot are the result of erroneous data. None of the plants have a nearest neighbor less than 5 cm away, so there must have been an error either in data entry or during the recording of GPS coordinates. Because we have records for the correct GPS coordinates of every plant, this will be a very easy error to fix, but had Stuart not looked closely at this plot, I may have done the entire analysis with incorrect data.

Much of the work I have been doing up to this point has been to determine a single number for each head—the proportion of all achenes on a given head that contain a fully formed seed, or seed set. This gives a good indication of how successful that plant was in terms of reproduction. The most likely reason that an achene does not contain a seed is that the flower did not receive compatible pollen, either due to a lack of mates or due to a limitation on the part of the pollinators.
In order to determine seed set, I need two numbers: the total number of achenes and the number of achenes containing an embryo. While the achenes could be counted by hand, this would be a tedious and error-prone process. Instead, the achenes were placed on a glass tray and scanned into the computer and counted digitally.
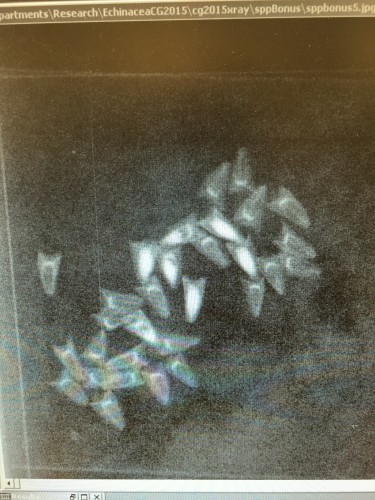
It is possible to determine whether or not an achene contains a seed by several methods. Germination experiments are useful because every achene that germinated certainly contained a seed, but they can be time-consuming and demand lots of attention and resources. Another possibility is to weigh the achenes. Heavier achenes are much more likely to contain a seed, and lighter achenes are most likely empty. We chose to use x-ray, which allows us to see directly inside of each achene. When achenes are x-rayed, empty achenes are barely visible while seeds show up as opaque. Ideally, all achenes could be easily categorized into “empty” or “full,” but some achenes are partially full, likely meaning they were initially fertilized but full seed growth was not entirely successful.
Together, these numbers are very important in allowing us to make inferences about what conditions are best for Echinacea reproduction.
 Randomized achenes ready to be x-rayed.
This is what x-rayed achenes look like. Achenes that contain a seed show up with a white oval in the center.  Full, partial, and empty achenes are counted on the computer and entered into an spreadsheet.
Randomization is a critical aspect of any experiment. In almost all cases, the population being studied is much too large to study every individual, so a sample of the population is studied with the assumption that trends and relationships seen in the sample are also present in the population as a whole. In order for this to be a good assumption, the sample must be completely random in order to eliminate any bias towards a specific type of individual.
In an ideal world, all samples would be completely random, but this is not logistically possible in many cases. For example, at Staffanson Prairie Preserve, there are thousands of Echinacea that bloom every year. It would be a near impossibility to visit every single plant or even to select a completely random sample of plants within the preserve. For this reason, the Echinacea Project created a 10-meter wide transect through the preserve and studies the plants that fall within this transect. While this is not a truly random sample, it is able to approximate the range of conditions seen throughout the preserve.
Another example of randomization is something I’ve been working on in the lab for the last week. Many of the heads contain several hundred achenes, so x-raying all of them to determine whether or not they contain a seed would be extremely time consuming and difficult. In order to simplify the process, I am randomly selecting 1/6th of the achenes from each head in order to estimate seed set for each head. While this will not give me the exact seed set, it will give me a very good approximation that will be sufficient for our analyses. Pictures of the randomization process are shown below—achenes are randomly dispersed on a wheel divided into twelve labeled sections of equal size. Next, two letters are selected from a list of random letters, and the achenes that fall within these sections are selected to be x-rayed.
Achenes on the randomization wheel Randomized achenes–labeled and ready for x-raying
For the past three weeks, I’ve been hard at work collecting the achenes from Echinacea heads that were collected last summer from Staffanson Prairie Preserve. A little bit of Echinacea anatomy to give you a better idea of what I’m talking about: each head typically consists of 100 to several hundred small flowers or florets. After the head has matured and the florets have finished blooming, every flower produces one fruit, known as an achene, regardless of whether or not it was fertilized. Back at the lab, we clean all the achenes off the heads in order to count them and determine whether or not they contain a viable seed.
An intact head Achenes In addition to cleaning the heads, I have also been separating the achenes by where on the head they were located. The florets bloom row-by-row starting from the base of the head and working their way up, so we know that the florets at the bottom bloomed first and the ones at the top bloomed last. Looking at reproductive success via seed set on the top, middle, or bottom of each head will thus give an indication of how the mating scene and pollen availability changed over the course of the mating season.
Hard at work cleaning a head Cleaning the heads is the first step in determining seed set, the primary measure of reproductive success I’ll be using for this project. Seed set is defined as the proportion of seeds that were successfully fertilized, and this number can range from zero to nearly 100%. While there are many reasons that fertilization may have failed, the primary reason is most likely a lack of compatible pollen. Now that all the achenes have been removed from the heads, I can determine what proportion of achenes on each head contains an embryo using x-ray. I’ll go into more depth about the x-raying process in another post.
I’ve been helping out around the lab since the fall, but this is my first post on the Flog, so I’ll go ahead and introduce myself. I’m Gordon, and I’m a senior at Northwestern University studying Environmental Science and Chemistry. I have the awesome opportunity to conduct an independent study here at The Echinacea Project—not only will I learn research techniques and scientific writing skills, but I’m also able to get class credit for my research, allowing me to devote more time to the project.
Me with one of the many heads I’ve dissected
The main focus of my research is how fires affect the reproductive success of Echinacea. The existing scientific literature suggests that fires (or a lack thereof) redistribute resource availability, giving a survival advantage to certain species of plants. For example, a fire can burn tall prairie grasses to the ground, allowing shorter plants to access sunlight and contributing to their survival. In areas where prairie fires are suppressed, which includes many locations where prairie remnants exist today, it is thought that plants that benefit from fires will become scarcer. However, there is scant scientific literature regarding how fires influence the reproductive success of prairie plants.
At Staffanson Prairie Preserve, prescribed burns are conducted every five years, providing an ideal setting in which to conduct this observational study. I will be examining at plants that flowered both in 2015 (a non-burn year) and in a previous burn year. By comparing their reproductive success in both the burn year and non-burn year, I hope to gain an understanding of what influence fires may have on Echinacea reproduction. The measures I will use to study reproductive success will include: achene count, which indicates resource availability and reproductive effort; style persistence, which measures the pollen availability and limitation; seed set, which measures the success rate of seed production; and fecundity, which serves as an indication of total reproductive success.
Stay tuned for weekly updates about my procedure and progress over the next several months!
|
|